27
Mar
Microsoft Azure delivers game-changing performance for generative AI Inference
Microsoft Azure has delivered industry-leading results for AI inference workloads among cloud service providers in the most recent MLPerf Inference results published publicly by MLCommons. The Azure results were achieved using the new NC H100 v5 series virtual machines (VMs) powered by NVIDIA H100 NVL Tensor Core GPUs and reinforced the commitment from Azure to designing AI infrastructure that is optimized for training and inferencing in the cloud.
The evolution of generative AI models
Models for generative AI are rapidly expanding in size and complexity, reflecting a prevailing trend in the industry toward ever-larger architectures. Industry-standard benchmarks and cloud-native workloads consistently push the boundaries, with models now reaching billions and even trillions of parameters. A prime example of this trend is the recent unveiling of Llama2, which boasts a staggering 70 billion parameters, marking it as MLPerf’s most significant test of generative AI to date (figure 1). This monumental leap in model size is evident when comparing it to previous industry standards such as the Large Language Model GPT-J, which pales in comparison with 10x fewer parameters. Such exponential growth underscores the evolving demands and ambitions within the AI industry, as customers strive to tackle increasingly complex tasks and generate more sophisticated outputs.
Tailored specifically to address the dense or generative inferencing needs that models like Llama 2 require, the Azure NC H100 v5 VMs marks a significant leap forward in performance for generative AI applications. Its purpose-driven design ensures optimized performance, making it an ideal choice for organizations seeking to harness the power of AI with reliability and efficiency. With the NC H100 v5-series, customers can expect enhanced capabilities with these new standards for their AI infrastructure, empowering them to tackle complex tasks with ease and efficiency.
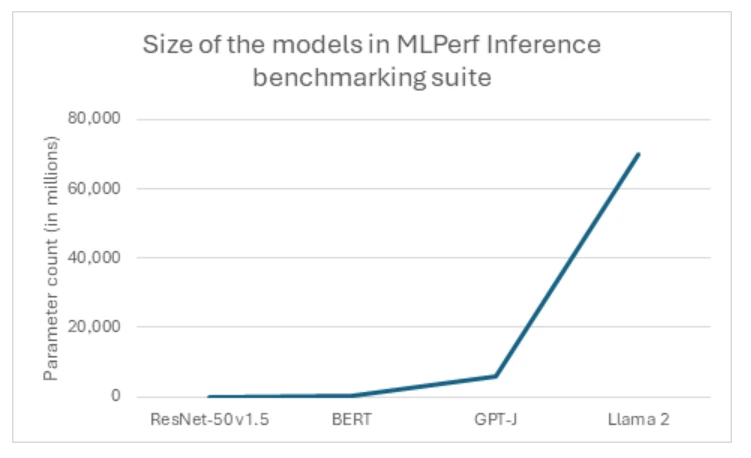
However, the transition to larger model sizes necessitates a shift toward a different class of hardware that is capable of accommodating the large models on fewer GPUs. This paradigm shift presents a unique opportunity for high-end systems, highlighting the capabilities of advanced solutions like the NC H100 v5 series. As the industry continues to embrace the era of mega-models, the NC H100 v5 series stands ready to meet the challenges of tomorrow’s AI workloads, offering unparalleled performance and scalability in the face of ever-expanding model sizes.

Enhanced performance with purpose-built AI infrastructure
The NC H100 v5-series shines with purpose-built infrastructure, featuring a superior hardware configuration that yields remarkable performance gains compared to its predecessors. Each GPU within this series is equipped with 94GB of HBM3 memory. This substantial increase in memory capacity and bandwidth translates in a 17.5% boost in memory size and a 64% boost in memory bandwidth over the previous generations. . Powered by NVIDIA H100 NVL PCIe GPUs and 4th-generation AMD EPYC™ Genoa processors, these virtual machines feature up to 2 GPUs, alongside up to 96 non-multithreaded AMD EPYC Genoa processor cores and 640 GiB of system memory.
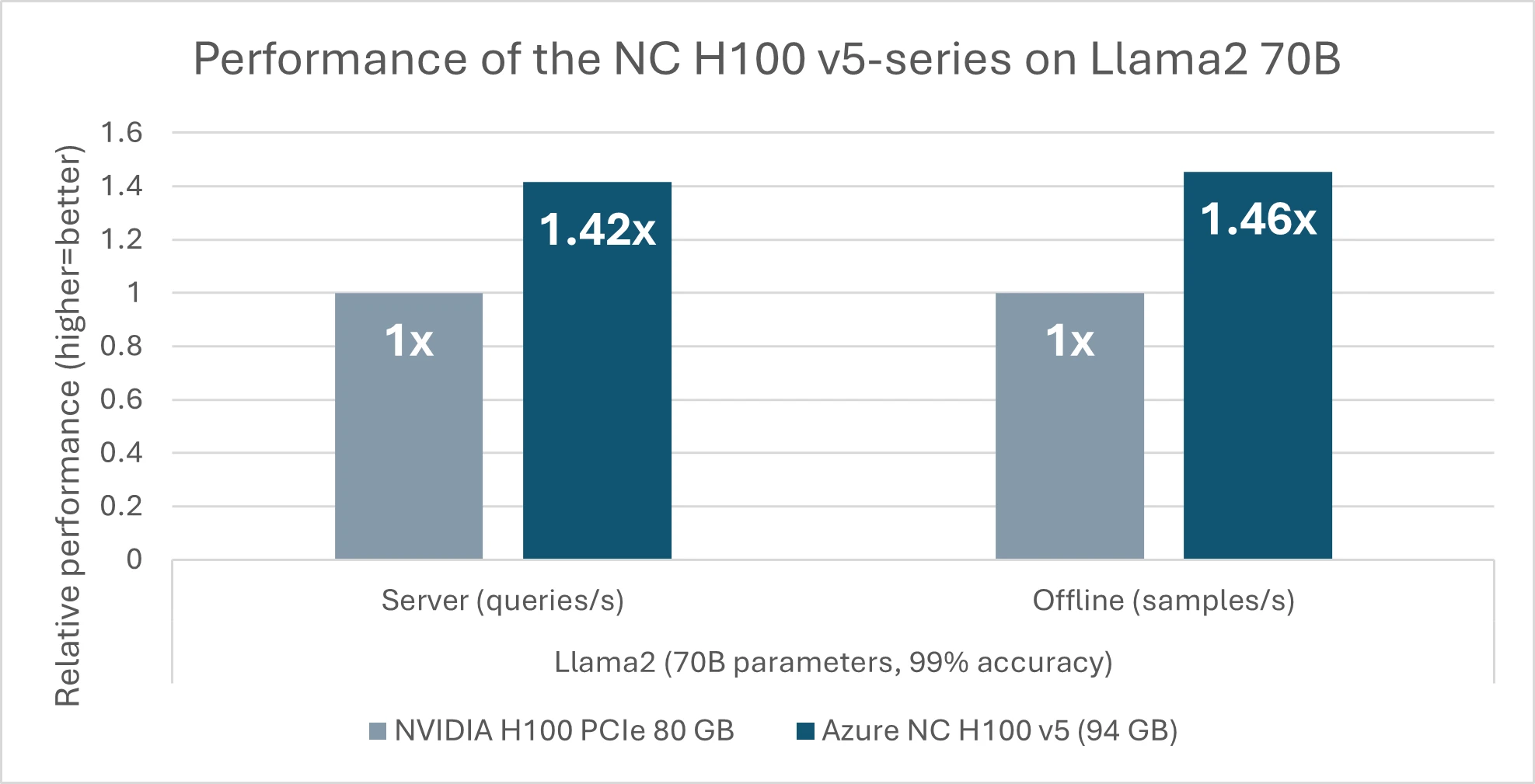
In today’s announcement from MLCommons, the NC H100 v5 series premiered performance results in the MLPerf Inference v4.0 benchmark suite. Noteworthy among these achievements is a 46% performance gain over competing products equipped with GPUs of 80GB of memory (figure 2), solely based on the impressive 17.5% increase in memory size (94 GB) of the NC H100 v5-series. This leap in performance is attributed to the series’ ability to fit the large models into fewer GPUs efficiently. For smaller models like GPT-J with 6 billion parameters, there is a notable 1.6x speedup from the previous generation (NC A100 v4) to the new NC H100 v5. This enhancement is particularly advantageous for customers with dense Inferencing jobs, as it enables them to run multiple tasks in parallel with greater speed and efficiency while utilizing fewer resources.
Performance delivering a competitive edge
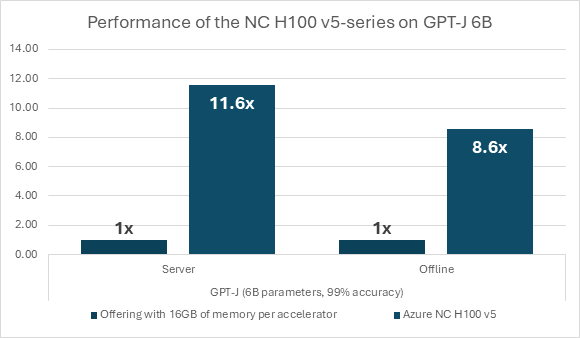
The increase in performance is important not just compared to previous generations of comparable infrastructure solutions In the MLPerf benchmarks results, Azure’s NC H100 v5 series virtual machines results are standout compared to other cloud computing submissions made. Notably, when compared to cloud offerings with smaller memory capacities per accelerator, such as those with 16GB memory per accelerator, the NC H100 v5 series VMs exhibit a substantial performance boost. With nearly six times the memory per accelerator, Azure’s purpose-built AI infrastructure series demonstrates a performance speedup of 8.6x to 11.6x (figure 3). This represents a performance increase of 50% to 100% for every byte of GPU memory, showcasing the unparalleled capacity of the NC H100 v5 series. These results underscore the series’ capacity to lead the performance standards in cloud computing, offering organizations a robust solution to address their evolving computational requirements.
In conclusion, the launch of the NC H100 v5 series marks a significant milestone in Azure’s relentless pursuit of innovation in cloud computing. With its outstanding performance, advanced hardware capabilities, and seamless integration with Azure’s ecosystem, the NC H100 v5 series is revolutionizing the landscape of AI infrastructure, enabling organizations to fully leverage the potential of generative AI Inference workloads. The latest MLPerf Inference v4.0 results underscore the NC H100 v5 series’ unparalleled capacity to excel in the most demanding AI workloads, setting a new standard for performance in the industry. With its exceptional performance metrics and enhanced efficiency, the NC H100 v5 series reaffirms its position as a frontrunner in the realm of AI infrastructure, empowering organizations to unlock new possibilities and achieve greater success in their AI initiatives. Furthermore, Microsoft’s commitment, as announced during the NVIDIA GPU Technology Conference (GTC), to continue innovating by introducing even more powerful GPUs to the cloud, such as the NVIDIA Grace Blackwell GB200 Tensor Core GPUs, further enhances the prospects for advancing AI capabilities and driving transformative change in the cloud computing landscape.
Learn more about Azure generative AI
- New Azure NC H100 v5 VMs Optimized for generative AI and HPC workloads is now generally available—Microsoft Community Hub
- NCads H100 v5-series—Azure Virtual Machines | Microsoft Learn
- Benchmark MLPerf Inference: Datacenter | MLCommons V4.0
The post Microsoft Azure delivers game-changing performance for generative AI Inference appeared first on Microsoft Azure Blog.